

C’est Google, qui cette fois-ci, fait parler d’elle en publiant les premières images créées artificiellement par leur réseau neuronal de reconnaissance d’images à qui l’on a «appris» à identifier certains objets. Comme vous le remarquerez, les résultats sont pour le moins surprenants!
C’est quoi un réseau de neurones artificiels?
Les réseaux de neurones artificiels sont des modèles de calcul appliqués à des machines informatiques dont la conception s’inspire grossièrement du fonctionnement des neurones biologiques, en gros, celles qui font fonctionner votre cerveau. La nouveauté vient de l’optimisation de leur fonctionnement via des méthodes d’apprentissage, dites de type probabiliste et adaptatif, qui leur permet «d’apprendre» comme le ferait un réseau neural biologique naturel. Ces neurones artificiels interconnectés s’envoient des messages entre eux dont le «poids» numérique peut être ajusté en fonction de l’expérience accumulée et du résultat recherché. Ces réseaux deviennent alors adaptables et peuvent «apprendre» en fonction de leur expérience au travers des données qui leur sont fournies par l’homme tout au long de leur «vie».
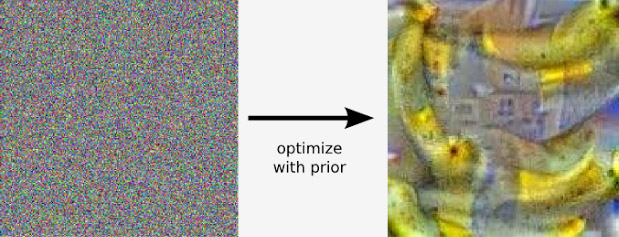

Dans le cas de Google, c’est pour leur service de classification d’images que les ingénieurs ont utilisé ce procédé, déjà largement éprouvé pour les reconnaissances vocale et écrite. Les images que vous voyez ci-dessous sont issues du procédé suivant. Les réseaux sont constitués de 10 à 30 couches successives de neurones artificiels. Chaque image est introduite dans la première couche qui parle à la seconde et ainsi de suite jusqu’à la dernière couche qui «répond» en fournissant une image.
Ok, mais pour quoi faire?
L’objectif : permettre d’identifier une quantité industrielle d’images grâce à des IA capables d’apprendre par elles-mêmes.
L’objectif des chercheurs de Google est simple : permettre de classer et d’identifier une quantité industrielle d’images grâce à des IA capables d’apprendre par elles-mêmes et de reconnaître un large panel d’objets. Comme un humain peut déceler des formes d’animaux dans les nuages, le réseau neural de Google peut lui aussi chercher à associer les nouvelles images qu’on lui soumet avec des requêtes qu’il a déjà traitées.
Mais là où l’exercice devient vraiment fascinant, c’est lorsque l’on raffine la recherche en demandant à l’IA de trouver des objets qui ne sont pas présents dans l’image. Le modèle produit alors des images résultantes d’expériences de classifications précédentes, enrichies par les images traitées par la suite, tout cela en fonction de la requête formulée pour la recherche.
Les couches successives de neurones ont aussi des sensibilités différentes, les plus basses cherchant des formes basiques, de gros traits et des bordures tandis que les strates plus élevées jonglent avec des concepts plus abstraits. Les résultats dépendent aussi donc grandement de l’importance accordée par les chercheurs au travail de telle ou telle couche neuronale. Avec la quantité d’images impressionnantes qui est soumise à Google chaque seconde, pas surprenant que ces ingénieurs essaient d’y mettre un peu d’ordre.
Et après, Skynet, c’est pour quand?

Même si l’on ne peut pas encore qualifier officiellement ce procédé «d’imagination» numérique à proprement parler, les progrès vers une indépendance de fonctionnement de certains algorithmes ont de quoi inquiéter. Si les ordinateurs sont désormais capables de détecter des objets qui n’étaient pas là au départ dans des images qu’en sera-t-il des autres domaines d’applications? Alors que l’on vient aussi d’apprendre que de nouveaux systèmes peuvent réussir à identifier des humains au visage caché sur des photos, on imagine rapidement les dérapages sécuritaires qui peuvent se produire dans un futur très proche.
Comme l’avait titré Philip K. Dick, il se pourrait bien que d’ici peu de temps, les androïdes rêvent vraiment de moutons électriques.



